FED: Fast and Efficient Dataset Deduplication
FED는 GPU 기반의 고속 대규모 텍스트 중복 제거 프레임워크로, 수천만 개 이상의 문서를 포함한 대규모 텍스트 데이터셋에서 유사한 문서 쌍을 효과적으로 식별하고
중복을 제거합니다.
FED는 MinHash LSH(Locality-Sensitive Hashing) 알고리즘을 GPU 클러스터 환경에 최적화하여 연산 속도를
극대화하였으며, 재사용 가능한 해시 함수를 도입하여 계산량을 효과적으로 줄였습니다.
FED는 3천만 개 이상의 문서를 포함한 영어 뉴스 데이터셋 RealNews에 대한 중복 처리 결과, 기존 CPU 기반 방식(SlimPajama) 대비 110배, 기존 GPU
기반 방식(NVIDIA NeMo Curator) 대비 6.6배 빠른 속도를 달성하였습니다.
속도 향상과 동시에 중복 제거 결과는 기존 방식들과 98% 이상의 유사도를 유지하여 정확성과 효율성을 모두 확보하였으며, 다중 GPU 및 멀티 노드 클러스터 환경에서의 분산
처리를 지원하여 확장성과 실용성을 겸비하고 있습니다.
FED is a GPU-accelerated framework for large-scale text deduplication. It identifies and
removes near-duplicate document pairs from massive text datasets containing tens of millions of
documents.
FED optimizes the MinHash LSH (Locality-Sensitive Hashing) algorithm for GPU
clusters and reduces computational overhead by partially reusing hash functions.
FED achieves up to 107× speedup over traditional CPU-based methods (e.g., SlimPajama) and up to 6×
faster performance compared to existing GPU-based systems (e.g., NVIDIA NeMo Curator) when
deduplicating the RealNews dataset, which contains over 30 million English news articles.
Despite the significant speed gains, FED maintains over 98% similarity in deduplication results
compared to baseline methods, ensuring both efficiency and accuracy. Moreover, FED supports
distributed processing across multi-GPU and multi-node clusters, offering excellent scalability for
real-world deployment.
텍스트 중복 제거는 대규모 언어 모델 학습을 위한 전처리 과정에서 매우 중요한 단계 중 하나입니다.
데이터셋 내 유사한 문서를 식별하고 제거함으로써 데이터 품질과 학습 효율성을 높이고, 결과적으로 언어 모델의 일반화 성능을 향상시키는 데 기여합니다.
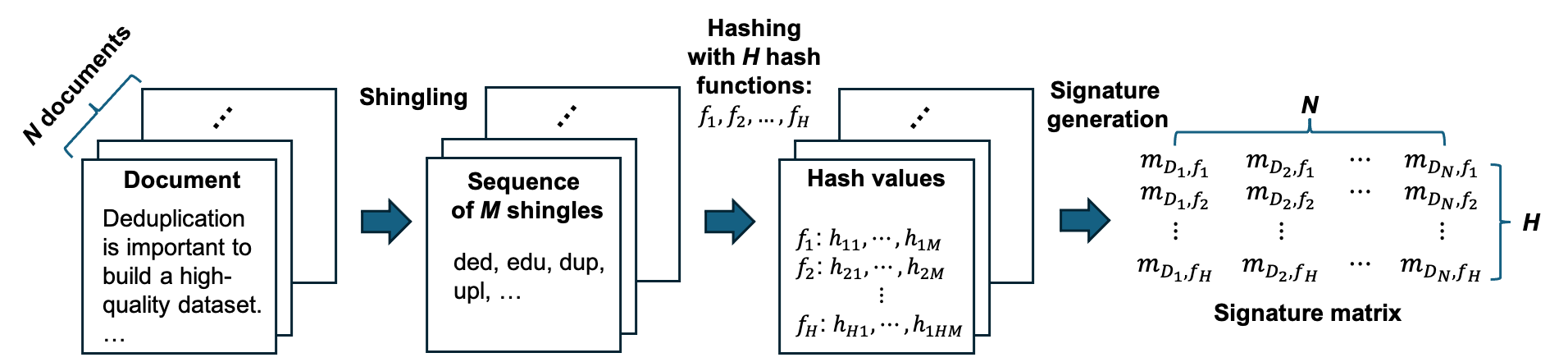
대표적인 중복 제거 알고리즘으로는 MinHash-LSH가 널리 사용됩니다. MinHash는 각 문서를 n-gram 단위의
shingles로 나눈 뒤, 각 shingle 집합에 대해 여러 개의 해시 함수를 적용하여 서명(signature) 벡터를 생성합니다.
이 서명 벡터는 원래 문서의 전체 shingle 집합을 압축한 형태로, 문서 간의 Jaccard 유사도를 근사하는 데 사용됩니다.
MinHash-LSH는 이 과정에서 서명 벡터들을 여러 버킷에 분산시켜 유사 문서를 빠르게 탐색할 수 있도록 합니다.
하지만 MinHash-LSH도 대규모 데이터셋에서는 여전히 해시 생성과 비교 과정에 상당한 시간이 소요됩니다. FED는 이러한 병목을 해결하기 위해 MinHash-LSH 알고리즘을
GPU에
최적화하여 훨씬 빠르고 효율적으로 중복 제거를 수행할 수 있도록 설계되었습니다.
Text deduplication is a critical preprocessing step in large-scale language model training.
By identifying and removing similar documents within a dataset, it improves data quality and
training efficiency, ultimately enhancing the generalization performance of the language
model.
One of the most widely used algorithms for deduplication is MinHash-LSH (Locality-Sensitive
Hashing). MinHash approximates each document as a compact hash signature to estimate similarity
between documents, while LSH distributes these signatures into multiple buckets to enable fast
retrieval of similar pairs.
However, with large-scale datasets, the hash generation and comparison steps can still be
computationally expensive. FED addresses this bottleneck by optimizing the MinHash-LSH algorithm for
GPUs, enabling much faster and more efficient deduplication at scale.
FED는 재사용 가능한 non-cryptographic 해시 함수를 도입하여 해시 생성 단계의 연산 시간을 획기적으로 줄였습니다.
또한 CUDA 기반의 GPU 연산 및 통신 최적화를 통해 해시 비교 단계에서도 빠른 처리가 가능해졌습니다.
그 결과, FED는 기존 CPU 기반 방식 대비 최대 110배, 기존 GPU 기반 방식(NVIDIA NeMo Curator) 대비 최대 6.6배 빠른 속도를 달성하였습니다.
FED의 전체 처리 과정은 아래 그림에 요약되어 있으며, 자세한 내용은 상기 링크의 논문에서 확인하실 수 있습니다.
FED significantly reduces computation time in the hash generation phase by introducing reusable
non-cryptographic hash functions.
In addition, GPU computation and communication optimizations based on CUDA enable fast processing in
the hash comparison phase as well.
As a result, FED achieves up to 110× speedup over CPU-based methods and up to 6.6× speedup over
GPU-based methods such as NVIDIA NeMo Curator.
The overall workflow of FED is illustrated in the figure below, and further details can be found in
the linked paper.
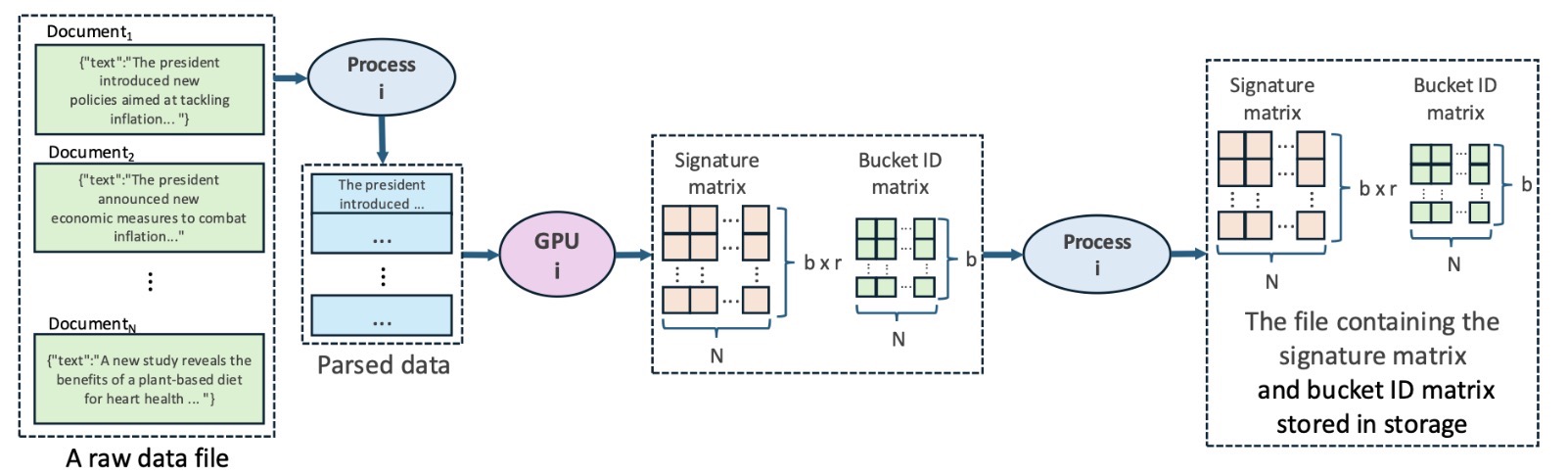
1. Signature Matrix 생성 및 각 밴드별 버킷 ID 계산
각 문서에 대해 signature 벡터를 계산하고, 이를 모아 signature matrix를 생성합니다.
그 후, 각 signature 벡터를 여러 구간으로 나누는 밴드(band) 단위로 처리하며, 각 밴드별로 문서가 속할 버킷 ID를 계산합니다.
모든 연산은 GPU에서 수행되며, 대규모 데이터셋에 대응하기 위해서, 생성된 signature matrix는 별도의 스토리지에 오프로딩하는 방식을 사용합니다.
1. Generating the signature matrix and calculating the bucket ID for each band.
For each document, a signature vector is computed and aggregated to form a signature matrix.
Next, each signature vector is divided into multiple segments called bands, and for each band, the
bucket ID that the document belongs to is calculated.
All computations are performed on the GPU, and to ensure scalability for large datasets, the
generated signature matrix is offloaded to external storage.
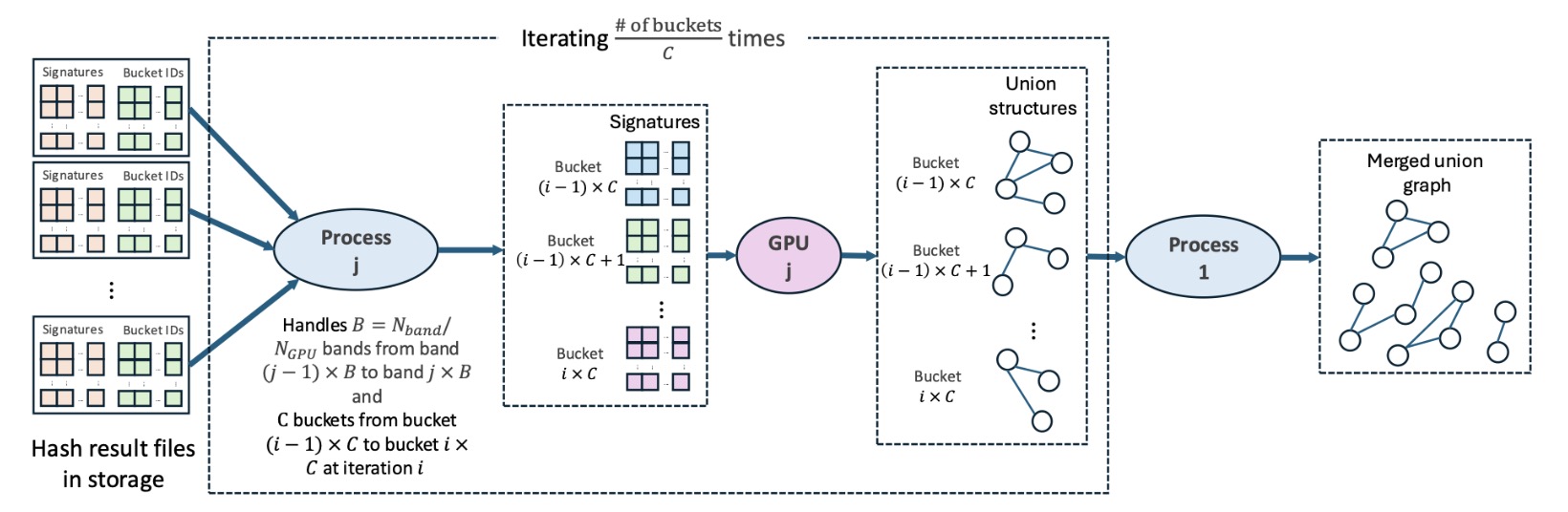
2. 문서 쌍별 비교 및 그래프 생성
같은 버킷에 속한 모든 문서 쌍에 대해 유사도를 계산하여 서로 유사한 문서들을 식별합니다.
이후, 유사한 문서 쌍들을 하나의 연결된 그래프(union graph) 형태로 구성하여, 각 문서가 어떤 다른 문서들과 중복 관계에 있는지를 파악하고 중복 문서들을 제거합니다.
2. Pairwise comparison and the union graph generation.
Through the pairwise comparison process, the similarity between every pair of documents in the
dataset is calculated to identify documents that are similar to each other.
Subsequently, the similar document pairs are organized into a union graph, which visually or
structurally represents the duplication relationships between documents.
본 연구는 과학기술정보통신부 선도연구센터사업(ERC)의 지원을 받아 수행된 연구입니다 (과제번호: RS-2023-00222663, 초거대 AI 모델 및 플랫폼 최적화 센터). 또한, GPU 장비는 과학기술정보통신부·광주광역시가 공동 지원한 '인공지능 중심 산업융합 집적단지 조성사업'의 지원을 받았습니다.
This work was supported by the National Research Foundation of Korea (NRF) under Grant No. RS-2023-00222663 (Center for Optimizing Hyperscale AI Models and Platforms, ERC). This research was also supported by Artificial intelligence industrial convergence cluster development project funded by the Ministry of Science and ICT(MSIT, Korea)&Gwangju Metropolitan City.
손영준+, 김채원*,
이재진*+
* 서울대학교 컴퓨터공학부
+ 서울대학교 데이터사이언스대학원
Youngjun Son+, Chaewon Kim*,
Jaejin Lee*+
*Department of Computer Science and Engineering, Seoul National
University
+Graduate School of Data Science, Seoul National University