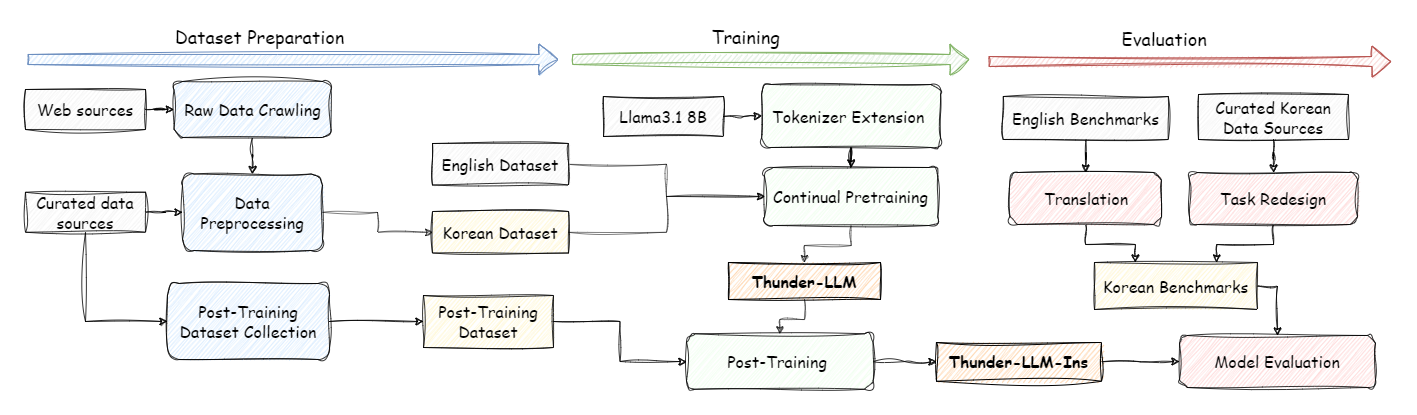
Llama-Thunder-LLM
Llama-Thunder-LLM은 LLaMA 3.1 8B 모델을
기반으로 개발한 한국어·영어 특화 LLM입니다.
Thunder-LLM Toolkit을 이용해 대량의 한국어·영어 데이터를 수집, 정제 및 가공한 뒤
연속 사전 학습(continual pre-training)과 SFT(Supervised Fine-Tuning), DPO(Direct Preference Optimization)
방식의
사후 학습(post training)을 진행했습니다.
모든 학습 과정은 FP8 혼합 정밀도로 진행되었으며, 이를 통해 학습 비용을 절감하면서도 최대한의 성능을 얻어냈습니다.
Llama-Thunder-LLM is a Korean-English specialized Large Language Model developed based on the LLaMA 3.1 8B model.
We utilized the Thunder-LLM Toolkit for both large-scale Korean
and English data collection, cleaning, and processing, as well as for continual pre-training and
post-training through SFT(Supervised Fine-Tuning) and DPO(Direct Preference Optimization).
All training processes were conducted using FP8 mixed precision, which allowed us to reduce training
costs while maximizing performance.
가장 먼저 학습용 한국어 데이터셋 구축을 위해 약 3TB 규모의 한국어 웹 데이터를 수집하였습니다. 이후 규칙 기반 전처리, GPU를 활용한 효율적인 중복 제거, 모델 기반의
데이터 필터링 과정을 거쳐 데이터를 정제하였습니다. 이후 영어 기반인 Llama3.1-8B 모델을 토대로, 영어 성능은 떨어지지 않으면서도 한국어 성능을 향상시키기 위해 영어
54B 토큰과 한국어 48B 토큰,
총 1.02조 개(102B 개) 토큰 규모의 데이터를 한국어와 영어 1:1 비율로 학습하였습니다.
이는 수십 조 규모의 토큰을 학습하는 기존의 거대 언어 모델 대비 획기적으로 적은 양입니다.
한국어 데이터를 보다 효율적으로 처리하기 위해 Thunder-Tok을 활용하여 약 92K개의 한국어
토큰을 모델의 어휘(토크나이저)에 추가하였습니다.
또한, 공개된 한국어와 영어 SFT(Supervised Fine-Tuning)* 데이터셋을 수집해 미세 조정을 하였으며, DPO(Direct
Performance Optimization)** 학습을 위해 언어 모델로부터 생성한 응답을 기반으로 정답 응답과 오답 응답을 포함하는 선호 학습 데이터셋을 구축하였습니다. 이를
통해 영어와 한국어에 특화된 이중 언어(bi-lingual) 모델을 개발하였습니다.
* SFT: 지도학습 방식으로 모델을 특정 과제에 적합하게 미세 조정하는 기법
** DPO: 사용자의 선호를 반영하여 모델의 응답을 직접적으로 최적화하는 기법
To begin constructing a Korean training dataset, we collected approximately 3TB of Korean web data. This data was then refined through rule-based preprocessing, efficient GPU-based deduplication, and model-based data filtering. Based on the English-pretrained Llama3.1-8B model, we further trained it with 54B English tokens and 48B Korean tokens—102B tokens in total—using a 1:1 ratio between Korean and English data, aiming to enhance Korean performance without degrading English capabilities. This is a significantly smaller amount compared to existing large language models that were typically trained on few trillions of tokens. To more efficiently process Korean text, we employed Thunder-Tok, adding approximately 92K Korean tokens to the model's vocabulary (tokenizer). In addition, we fine-tuned the model using publicly available Korean and English Supervised Fine-Tuning (SFT) datasets. For Direct Preference Optimization (DPO) training, we built a preference dataset consisting of both preferred and non-preferred responses generated by the language model. Through this process, we developed a high-performance bilingual model optimized for both English and Korean.
기존의 대형 언어 모델들은 학습 과정 전체를 공개하지 않아, 이를 그대로 구현하거나 재현하는 데 큰 어려움이 따릅니다. 데이터 구성, 전처리 절차, 하이퍼파라미터, 학습
방식 등 핵심적인 요소들이 명확히 드러나지 않기 때문에, 실제로 언어 모델을 처음부터 끝까지 직접 만들어보려는 시도는 여러 제약에 부딪힐 수밖에 없습니다. 게다가 언어 모델을
훈련하고 평가하는 데 필요한 고품질 데이터를 충분히 확보하기도 쉽지 않아, 실험을 시작하는 것 자체가 높은 진입 장벽이 됩니다. 뿐만 아니라, 많은 연구나 오픈소스 모델들은 전체
학습 파이프라인을 다루기보다는, 모델 아키텍처나 또는 파인튜닝 기법 등 일부 구성 요소에만 집중하는 경향이 있었습니다.
특히, 한국어에 대한 효율적인 처리를 위해 Thunder-Tok을 도입하였습니다. 생성형 언어 모델은 한 번에 하나의
토큰만 생성할 수 있기 때문에, 문장을 표현하는 데 필요한
토큰 수가
적을수록 추론 속도와 비용이 크게 줄어듭니다. 하지만 기존의 토크나이저들은 한국어에 비효율적입니다. 예를 들어, Llama-3.1의 기본 토크나이저는 한국어 토큰을 거의 포함하고
있지 않아,
한국어 문장을 표현하는 데 필요한 단어당 토큰 수가 매우 많고, EXAONE-3.5는 형태소 단위의 토큰화로 한국어의 의미 단위를 잘 보존하나, "할 수 있다"와 같은 자주
등장하는 한국어 구문조차
형태소 단위로 토큰화 하여, 지나치게 많은 토큰을 필요로 합니다.
Thunder-Tok은 이러한 문제를 해결하기 위해 한국어의 언어적 특성을 정밀하게 반영하여 설계된 토크나이저입니다. 자주 사용되는 구문을 하나의 토큰으로 처리할 수 있도록
학습하면서도,
한국어의 의미 단위를 보존하는 토큰화 결과로 모델의 성능도 높게 달성할 수 있도록 합니다. 이를 통해 Llama-Thunder-LLM은 기존 모델들보다 훨씬 효율적으로 한국어를
처리할 수 있습니다.
실제로 4개의 한국어 벤치마크에 대해 단어당 토큰 수를 비교한 결과, Llama-Thunder-LLM은 Llama-3.1 대비 약 44%, EXAONE-3.5 대비 약 29% 적은
단어당 토큰 수를 기록하였습니다.
이는 추론 비용 및 에너지 절감(Google 검색 한 번엔 평균 0.3Wh 전력이 쓰이는데 ChatGPT는 한 번에 2.9Wh를 소모)과 함께 한국어 처리 효율을 크게 향상시켰음을
보여줍니다.
전체 작업 결과와 과정을 모두 공개함으로써 Llama-Thunder-LLM은 후속 및 재현 연구에 활용될 수 있는 기반을 마련할 수 있도록 하였습니다.
Most existing large language models do not fully disclose their entire training processes, making it
difficult to replicate or reproduce them exactly. Key aspects such as data composition,
preprocessing procedures, hyperparameter, and training methods are often not clearly revealed, which
imposes significant limitations on attempts to build language models from scratch. Additionally,
obtaining high-quality data necessary for training and evaluating language models is challenging,
creating a high barrier to entry for experimentation. Moreover, many studies and open-source models
tend to focus only on specific components—such as model architectures or fine-tuning techniques
rather than covering the complete training pipeline.
Llama-Thunder-LLM is the result of an end-to-end approach that encompasses every stage of model
development—from data collection and preprocessing to tokenizer design, model training, and
evaluation—differentiating
it from prior studies. All training data were constructed independently without relying on publicly
available datasets,
enhancing both data quality and flexibility of use. Advanced training techniques such as continual
learning,
FP8-based mixed-precision training, and parallelization methods were actively applied to reduce
training costs efficiently.
To enable efficient Korean language processing, Thunder-Tok was
introduced. Generative language
models produce one token at
a time, so reducing the number of tokens required to represent a sentence directly improves
inference speed and lowers
computational costs. However, existing tokenizers tend to be inefficient for Korean. For example,
the default tokenizer of
Llama-3.1 contains few Korean tokens, resulting in a high number of tokens per word. EXAONE-3.5,
while preserving Korean morphological
units through subword tokenization, often over-segments frequently used expressions such as "할 수 있다"
("can do"), leading to unnecessarily
high token counts.
Thunder-Tok addresses these challenges by incorporating linguistic characteristics of Korean into
its design. Frequent expressions are encoded
as single tokens, while semantic units specific to Korean are preserved. This results in compact yet
meaningful tokenization that supports
better model performance. Llama-Thunder-LLM thus enables significantly more efficient Korean
language processing compared to existing models.
In evaluations across four Korean benchmarks, Llama-Thunder-LLM demonstrated approximately 44% fewer
tokens per word compared to Llama-3.1
and about 29% fewer than EXAONE-3.5.
This indicates significant improvements in Korean language processing efficiency, as well as
reductions in inference cost and energy consumption
(Google search consumes an average of 0.3Wh, a single ChatGPT query uses around 2.9Wh).
By publicly releasing both the full development process and resulting models, Llama-Thunder-LLM
provides a robust foundation for reproducibility
and future research, particularly in the development of Korean-optimized language models.
| Model | Tokens per Word (lower is better) | ||||
|---|---|---|---|---|---|
| Kobest-Hellaswag | Kobest-COPA | Ko-LAMBADA | Ko-Arc-e | Average | |
| Llama-3.1 | 2.686 | 2.916 | 2.538 | 2.576 | 2.679 |
| EXONE-3.5 | 2.052 | 2.272 | 2.135 | 1.991 | 2.113 |
| Llama-Thunder-LLM | 1.416 | 1.548 | 1.624 | 1.438 | 1.507 |
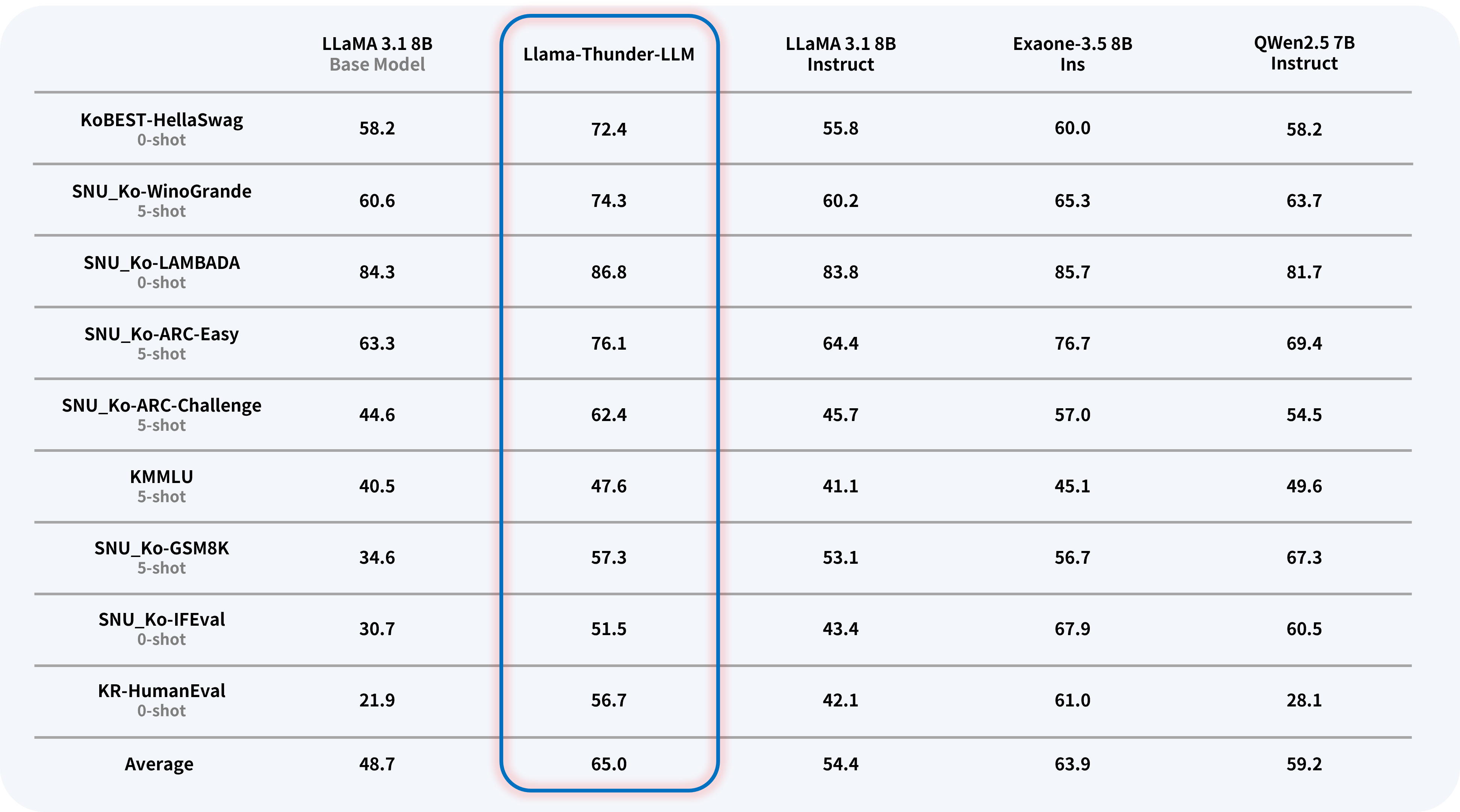
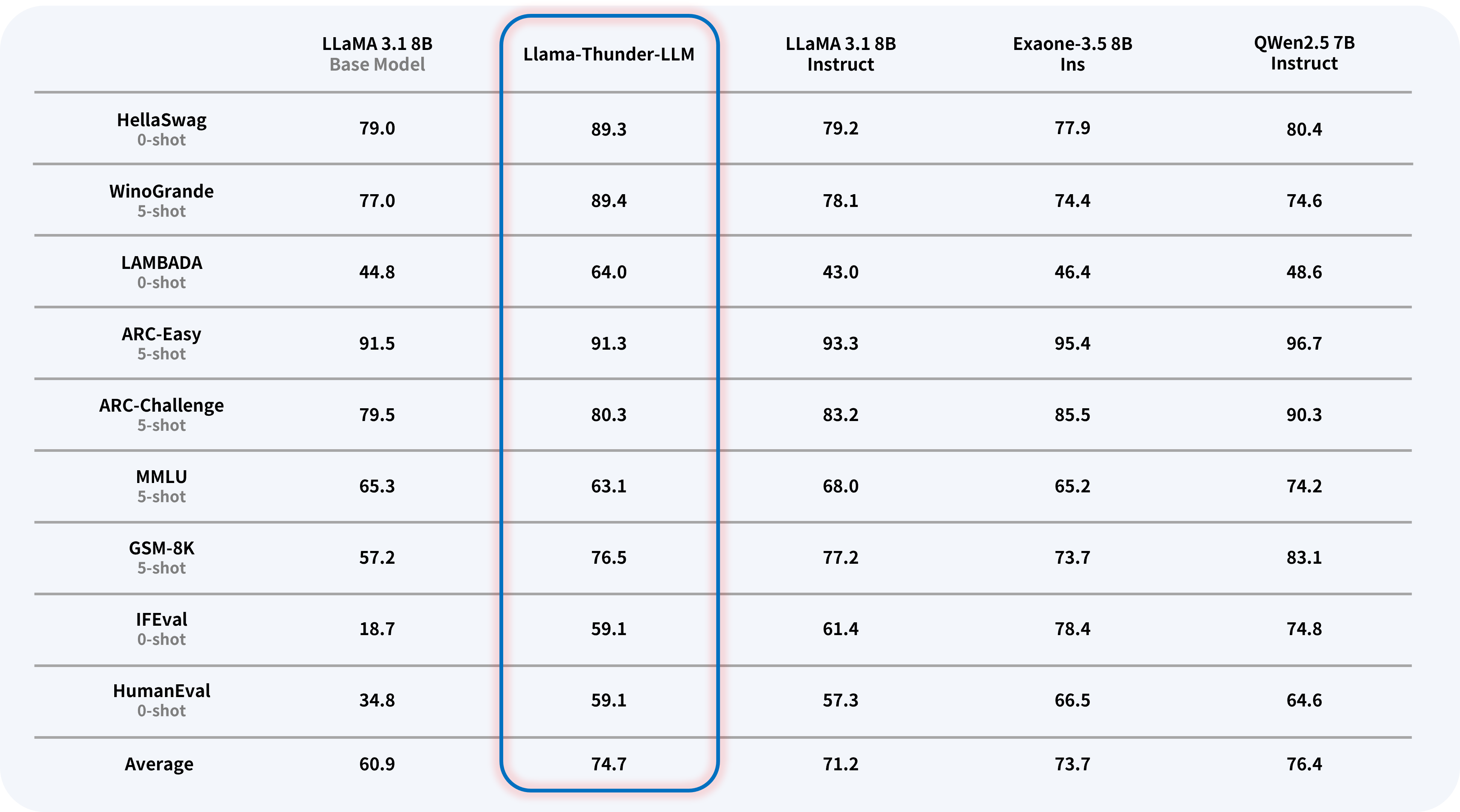
Llama-Thunder-LLM은 유사한 크기의 타 모델들과 비교했을 때 한국어에서 최고 수준의 성능을, 영어에서 준수한 성능을 보여줍니다.
Llama-Thunder-LLM demonstrates top-tier performance in Korean and competitive performance in English when compared to similar-sized models.
본 연구는 과학기술정보통신부 선도연구센터사업(ERC)의 지원을 받아 수행된 연구입니다 (과제번호: RS-2023-00222663, 초거대 AI 모델 및 플랫폼 최적화 센터). 또한, GPU 장비는 과학기술정보통신부·광주광역시가 공동 지원한 '인공지능 중심 산업융합 집적단지 조성사업'의 지원을 받았습니다.
This work was supported by the National Research Foundation of Korea (NRF) under Grant No. RS-2023-00222663 (Center for Optimizing Hyperscale AI Models and Platforms, ERC). This research was also supported by Artificial intelligence industrial convergence cluster development project funded by the Ministry of Science and ICT(MSIT, Korea)&Gwangju Metropolitan City.
김진표*, 조경제+, 박찬우*, 박종원*, 김종민+,
소연경+,
이재진*+
* 서울대학교 컴퓨터공학부
+ 서울대학교 데이터사이언스대학원
Jinpyo Kim*, Gyeongje Cho+, Chanwoo Park*, Jongwon
Park*,
Jongmin Kim+,
Yeonkyung So+,
Jaejin Lee*+
*Department of Computer Science and Engineering, Seoul National
University
+Graduate School of Data Science, Seoul National University