SNU Thunder-DeID
SNU Thunder-DeID는 한국어 법원 판결문 내 개인정보 등의 비식별화(De-identification)를 자동화하기 위해 수행된 프로젝트입니다. 개체명 인식(Named Entity Recognition, NER) 기술을 기반으로 판결문 내 사건 관계인을 식별할 수 있는 정보를 탐지하고, 이를 알파벳으로 치환하여 비식별화합니다. SNU Thunder-DeID는 모델, 데이터셋, 학습용 데이터셋 생성 코드, 추론용 툴킷으로 구성되어 있습니다.
본 페이지에서는 판결문 비식별화 모델 학습을 위한 SNU Thunder-DeID 데이터셋과, 이를 딥러닝 모델 학습에 사용할 수 있는 형태로 가공하는 데이터셋 생성 코드를 소개합니다.
SNU Thunder-DeID 데이터셋은 한국어 판결문 비식별화 모델 학습을 위한 데이터셋입니다.
라벨링된 판결문 데이터셋과 개체명 목록 데이터셋으로 구성되어 있습니다.
라벨링된 판결문
실제 한국어 형사 판결문에서 비식별화할 개체가 표시되어 있는 텍스트 데이터셋입니다.
강제추행, 폭행, 사기의 세 가지 사건 유형별로 각 1,500건씩 총 4,500건의 문서로 구성되어 있습니다.
총 27,402개의 비식별화 대상 개체가 포함되어 있으며, 문서 내 모든 개체는 해당 유형에 맞는 플레이스홀더(placeholder)로 표시되어 있습니다.
각 문서에 포함된 개체 유형은 형사소송법 등 관련 법령과 대법원 법원행정처의 판결문 비식별화 기준을 충실히 반영하여 선정되었습니다.
피고인은 2020. 11. 12. 00:40경부터 00:50경 사이 대전 서구 <<<구아래주소>>>B<<</구아래주소>>>에 있는 <<<병원>>>C<<</병원>>>병원 응급실 원무과 앞에서 진료비를 납부하지 않고 병원 밖으로 나가려고 하던 중 보안요원인 피해자 <<<내국인이름>>>D<<</내국인이름>>>(남, 27세)가 피고인을 제지하자 주먹으로 피해자의 머리 부위를 1회 가격하여 폭행하였다.
At approximately 00:40 to 00:50 on November 12, 2020, the defendant attempted to leave the emergency department administration office of <<<Hospital>>>C<<</Hospital>>> located at <<<SubdistrictAddress>>>B<<</SubdistrictAddress>>> in Seo-gu, Daejeon, without paying the medical fees. When the victim, a security guard named <<<KoreanName>>>D<<</KoreanName>>> (male, 27 years old), tried to stop the defendant, the defendant struck the victim once on the head with a fist.
개체명 목록
라벨링된 판결문의 각 문서 내 플레이스홀더에 삽입할 수 있는 개체명 목록을 유형별로 제공하는 보조 데이터셋입니다.
총 595개 개체 유형에 대해 최소 5개에서 최대 500개까지의 개체명이 수록되어 있으며, 대부분의 유형은 100개 이상의 예시를 포함합니다.
{
"공인중개사": [ "양문공인중개사", "삼우김동준공인중개사", "역삼중앙공인중개사", "신선비공인중개사", "LBA다홍공인중개사사무소", "동우공인중개사 사무소", ... ],
"상가": [ "봉곡진보프라자상가", "남대문중앙상가", "이상가", "은성상가", "99번상가", "시유 헬리오 2상가", "둔촌종합상가", "선주상가", "삼성상가", "동남종합상가", ... ],
"한식당": [ "명성불고기", "봄이보리밥", "물왕", "진이네도시락공방", "당골식당", "대홍집", "승한식당", "원골식당", "해누리", "밥집", "색동저고리", ... ],
...}
{
"Real Estate Agency": [ "Yangmoon Real Estate Agency", "Samwoo Kim Dongjun Real Estate", "Yeoksam Central Realty", "Shinseonbi Realty", "LBA Dahong Real Estate Office", "Dongwoo Realty Office", ... ],
"Shopping Complexes": [ "Bonggok Jinbo Plaza", "Namdaemun Central Complex", "Lee Shopping Center", "Eunseong Complex", "No. 99 Complex", "Siyu Helio 2 Complex", "Dunchon General Complex", "Seonju Complex", "Samsung Complex", "Dongnam General Complex", ... ],
"Korean Restaurants": [ "Myeongseong Bulgogi", "Bomi Barley Rice", "Mulwang", "Jin's Lunchbox Workshop", "Dangol Restaurant", "Daehong House", "Seung Han Restaurant", "Wongol Restaurant", "Haenuri", "Bapjip", "Saekdong Jeogori", ... ],
...}
데이터셋 생성 방법
모델 훈련에는 문장 그대로의 텍스트가 아닌, 문장을 일정한 단위(단어, 형태소 등)로 나눈 토큰의 시퀀스를 입력해야 합니다. 이러한 과정을
토큰화(tokenization)라고 하며 각 토큰은 고유한 정수 ID로 매핑되어 모델에 입력됩니다.
본 데이터셋은 라벨링된 판결문을 토큰화하는 과정에서 플레이스홀더에 실제 개체명의 토큰을 삽입하는 방식으로 생성됩니다.
이때 각 플레이스홀더의 시작과 끝(예: <<<내국인이름>>>,
<<</내국인이름>>>)은
토크나이저에 스페셜 토큰으로 등록되며, 가장 높은 우선순위로 처리되어 개체 경계가 분리되지 않도록 보장합니다.
문서 내 모든 플레이스홀더에 대해 개체명 목록에서 해당 유형에 맞는 개체명을 자동으로 할당한 뒤,
해당 문자열을 토큰화하여 스페셜 토큰 사이에 삽입하고 나머지 텍스트는 일반적인 방식으로 토큰화합니다. 스페셜 토큰은 개체 경계를 명확히 하기 위한 목적으로만 사용되며 최종 토큰
ID 시퀀스와 정답 라벨 시퀀스에는 포함되지 않습니다.
이렇게 생성된 토큰 ID 시퀀스와 정답 라벨 시퀀스 모델 학습에 직접 사용됩니다.
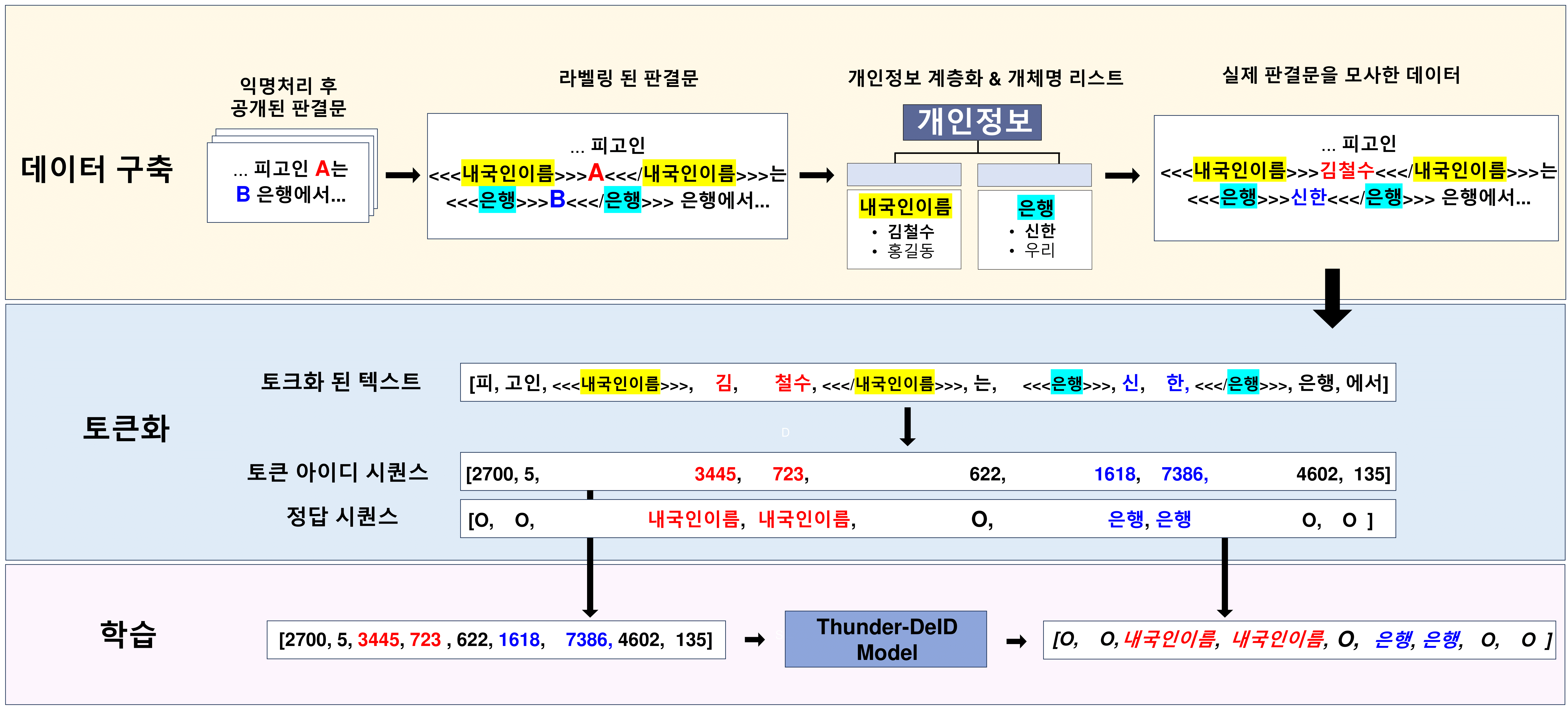
데이터셋 생성 코드는 라벨링된 판결문와 개체명 목록을 결합하여 실제 학습에 사용할 수 있는 문장을 생성합니다.
하나의 문서에 대해 다양한 개체 조합을 적용해 여러 개의 샘플을 생성할 수 있으며 이렇게 생성되는 문장의 수(증강 횟수)는 사용자가 자유롭게 설정할 수 있습니다.
생성된 데이터셋은 PyTorch 기반 모델 학습에 바로 사용할 수 있도록 입력 토큰 시퀀스(key: tokens) 텐서와 이에 대응하는 라벨 시퀀스(key: labels) 텐서를
포함합니다.
또한 디버깅과 결과 확인을 용이하게 하기 위해 개체 삽입 전의 원문 텍스트(key: raw), 개체 삽입이 적용된 텍스트(key: adjusted),
그리고 각 개체의 삽입 위치와 유형을 나타내는 정보(key: replace_link)도 함께 제공합니다.
{
'raw': '피고인은 2020. 9. 25. 23:45경 포항시 남구
<<<구아래주소>>>B<<</구아래주소>>>에 있는
피해자 <<<내국인이름>>>C<<</내국인이름>>>(여, 62세) 운영의 ...'
'replaced':{
'replace_link': [('B', '구아래주소'), ('C', '내국인이름'), ('D', '주점'), ('E', '구아래주소'), ('F', '빌딩')],
'adjusted': '피고인은 2020. 9. 25. 23:45경 포항시 남구 운하로에 있는 피해자 김연견(여, 62세) 운영의 ...'
...
}
}
{
'raw': 'The defendant, at around 23:45 on September 25, 2020, in Nam-gu, Pohang-si
<<<Subdistrict Address>>>B<<</Subdistrict Address>>>,
operated by the victim <<<Korean Name>>>C<<</Korean Name>>>
(female, 62 years old)...'
'replaced': {
'replace_link': [('B', 'Subdistrict Address'), ('C', 'Korean Name'), ('D', 'Bar'), ('E',
'Subdistrict Address'), ('F', 'Building')],
'adjusted': 'The defendant, at around 23:45 on September 25, 2020, in Unha-ro, Nam-gu,
Pohang-si, operated by the victim Kim Yeongyeon (female, 62 years old)...'
...
}
}
본 연구는 과학기술정보통신부 선도연구센터사업(ERC)의 지원을 받아 수행된 연구입니다 (과제번호: RS-2023-00222663, 초거대 AI 모델 및 플랫폼 최적화 센터). 또한, GPU 장비는 과학기술정보통신부·광주광역시가 공동 지원한 '인공지능 중심 산업융합 집적단지 조성사업'의 지원을 받았습니다.
This work was supported by the National Research Foundation of Korea (NRF) under Grant No. RS-2023-00222663 (Center for Optimizing Hyperscale AI Models and Platforms, ERC). This research was also supported by Artificial intelligence industrial convergence cluster development project funded by the Ministry of Science and ICT(MSIT, Korea)&Gwangju Metropolitan City.
함성은+, 김희진+, 이규성+, 박현지+,
박종연+, 표세호+, 이준학+, 정성목+, 김상호+,
이재진*+
* 서울대학교 컴퓨터공학부
+ 서울대학교 데이터사이언스대학원
Sungeun Hahm+, Heejin Kim+, Gyuseong Lee+, Hyunji Park+,
Jongyeon Park+, Seho Pyo+, Joonhak Lee+, Sungmok Jung+,
Sangho Kim+,
Jaejin Lee*+
*Department of Computer Science and Engineering, Seoul National
University
+Graduate School of Data Science, Seoul National University